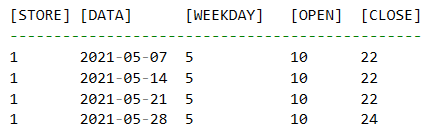Na jornada da análise de dados, a extração e organização de informações valiosas é crucial para embasar decisões estratégicas. Ao trabalhar com dados armazenados em bases de dados SQL, surge a necessidade de extrair esses dados e visualizá-los de maneira mais acessível e compreensível.
Nesse cenário, o Python destaca-se com sua biblioteca Pandas, oferecendo recursos poderosos para manipulação e análise de dados. A função to_excel do Pandas e a classe ExcelWriter são ferramentas essenciais nesse processo.
A função to_excel é uma funcionalidade simples e direta do Pandas, permitindo a exportação fácil e rápida de DataFrames para arquivos Excel. Com apenas algumas linhas de código é possível transformar conjuntos de dados complexos em planilhas estruturadas e visualmente atrativas.
Por outro lado, a classe ExcelWriter oferece um controle mais granular sobre a formatação do arquivo Excel. Ela permite a criação de arquivos mais elaborados, possibilitando a definição de configurações específicas, como formatação de células, múltiplos separadores, estilos e muito mais.
Essas ferramentas tornam-se fundamentais para profissionais e equipas que pretendem criar relatórios detalhados, dashboards ou compartilhar resultados de análises de dados de forma acessível e amigável para diferentes stakeholders.
Além disso, a capacidade de exportar dados SQL diretamente para um arquivo Excel simplifica o processo de comunicação entre equipas, facilitando a compreensão e a interpretação dos dados por partes interessadas que não estão familiarizadas com linguagens de consulta de base de dados.
Em resumo, a função to_excel e a classe ExcelWriter são recursos valiosos do Pandas que desempenham um papel crucial na transformação de dados SQL em visualizações ricas e formatadas em Excel. Essas ferramentas simplificam o processo de geração de relatórios e fortalecem a comunicação de insights vitais derivados da análise de dados.
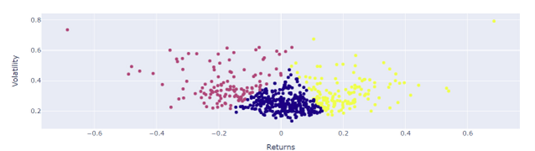
O seguinte trabalho pretende fazer a Classificação de títulos de bolsa nacionais e internacionais com base no algoritmo K-Means, um problema de classificação não supervisionada (clustering) que agrupa objetos em “k” número de grupos baseados nas suas características.
O intuito deste trabalho é encontrar as melhores ações de bolsa a nível “mundial”, através dos seus indicadores de Retorno e Volatilidade anuais, com base no histórico dos últimos dois anos. Termino com uma seleção de títulos “apetecíveis” especificando os seus valores atuais em bolsa.
O trabalho passa por diferentes métodos de Data Science e é todo realizado em Python:
obtenção de dados da web através de Web Scrapping,
tratamento dos mesmos em Pandas,
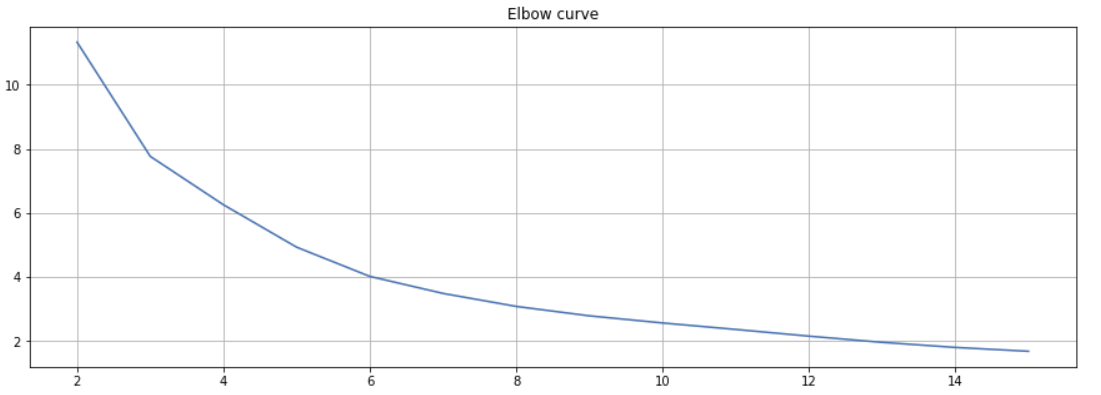
aplicação do modelo de classificação K-means, começando por procurar o melhor do número de clusters (“k”),
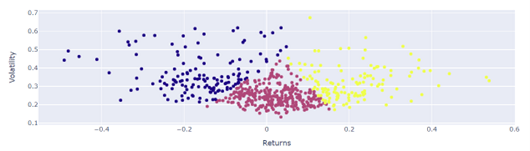
remoção de outliers,
seleção das melhores ações com retorno anual igual ou acima de 10% e volatilidade abaixo de 40% (escolha pessoal!),
obtenção dos preços atuais dos títulos da alínea anterior,
amostragem final das “melhores” ações em diferentes colorações consoante o seu preço
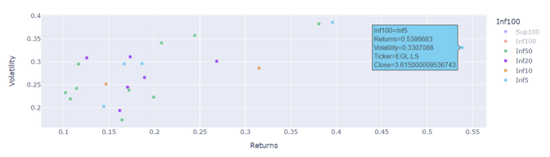
Elbow curve – escolha do número de clusters para o algoritmo k-means (k=3):
Classificação de títulos implementando 3 Clusters face ao Retorno e Volatilidade anuais:
Remoção de outliers:
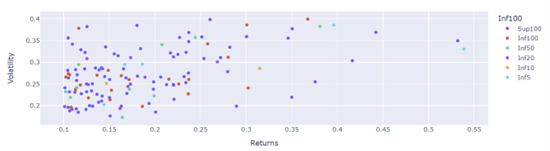
Títulos com Rentabilidade acima de 10% ao ano e Volatilidade inferior a 40%:
Seleção de títulos com preços abaixo de 50€:
O script Python (jupyter) está disponível no GitHub, sendo esta a conclusão final:
valor até 5€: o título EGL.LS é o que mostra maior retorno com uma taxa de volatilidade abaixo dos 35%. Logo de seguida o BCP.LS
inferior a 10€: o título BBVA.MC tem um retorno acima de 30% e volatilidade abaixo dos 30%
inferior a 20€ ou 50€: se optarmos por um título mais estável, abaixo dos 20% de volatilidade, temos a SEM.LS (inf20) e o DTE.DE (inf50)
” Introducing the k-means algorithm The term k-means was first used by MacQueen in 1967, although the idea dates back to Steinhaus in 1957. K-means is an unsupervised classification (clustering) algorithm that groups objects into k groups based on their characteristics.
Clustering is done by minimizing the sum of distances between each object and the centroid of its group or cluster. Quadratic distance is often used. The algorithm consists of three steps:
Initialization: once the number of groups, k, has been chosen, k centroids are established in the data space, for example, choosing them randomly. Assign objects to centroids: each data object is assigned to its nearest centroid. Centroid update: the position of the centroid of each group is updated, taking as the new centroid the position of the average of the objects belonging to said group. Steps 2 and 3 are repeated until the centroids do not move, or move below a threshold distance at each step.
num projecto recente de previsão de séries temporais fui dirigido para um determinado tema que, de uma forma muito simples, pode “copiar” tabelas de Websites para o Python (Pandas).
Já havia trabalhado com Pandas e SQL, ou CSV, mas conseguir dados de html só mesmo com algo mais profundo na área de Web Scraping…
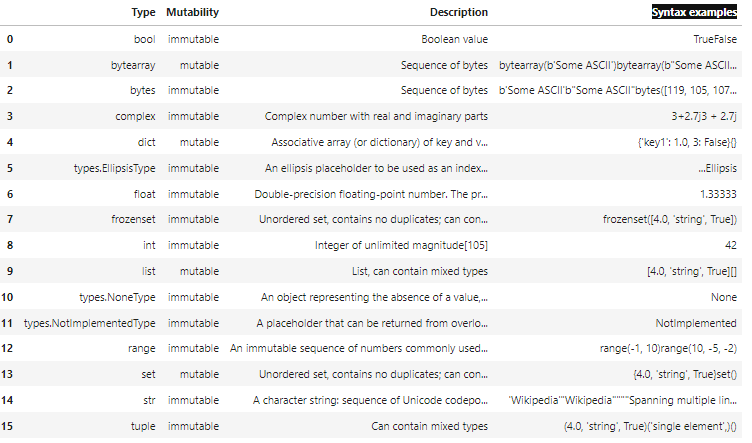
Para o caso aqui é muito mais simples, basta utilizar a função read_html() .
Esta função consegue ler tudo que seja <table> em html e importar para o Pandas.
import pandas as pd url = ‘_https://en.wikipedia.org/wiki/Python_(programming_language)’
pd.read_html(url)
Com isto, o Pandas importa todas as tabelas que encontrar na página html, separando-as por vírgula. De seguida, deveremos concentrar o pedido na tabela desejada, invocando a sua posição no vector, neste caso quero a segunda tabela (os índices começam em zero).
python_types = pd.read_html(url)[1] python_types
Por fim, se der jeito, poderemos exportar esta tabela para Excel:
Este foi apenas um caso simples para utilização desta função do Pandas. Claro que pode ser muito mais útil e complexo se pretendermos agora juntar duas ou mais tabelas antes de exportar para Excel.
Olá, uma das ferramentas com que lido diariamente são as Power Apps. Em determinada altura surgiu a necessidade de colocar uma dessas aplicações em estado inacessível. O propósito prende-se com a necessidade da app ficar disponível apenas duas semanas por mês, evitando alterações aos dados nas outras semanas.
Na procura por algo que ajudasse, eis que surgiu a resposta na net: “How to turn app off temporarily?
“…Model-Driven Apps can be Deactivated via the maker portal. For Canvas Apps, there is no deactivate option unfortunately, so your best bet would be to modify the app permissions so that only yourself/admins can access it. For an On-Premise Data Gateway, you can similarly modify the permissions so only admins have access. The other option is to stop and disable the Gateway service on your servers where the gateway is installed… ”
Alterar permissões ou definições do gateway pode significar problemas noutras apps, além da necessária reconfiguração para ativar/inativar a app.
Algumas formas de abordar a inativação da app sem recorrer à solução anterior poderiam ser estas:
1) Alterar ao nível do SQL: se a app se basear numa tabela temporária onde possam ser eliminados ou alteradas permissões aos dados até à próxima atualização seria uma possibilidade – o utilizador acederia à app e não poderia fazer alterações por não ver registos ou ter apenas acesso de visualização. 2) Alterar ao nível da app: no local de edição dos registos colocar o modo “DisplayMode.Disabled” ou “DisplayMode.View”, em detrimento de “DisplayMode.Edit”. Para automatizar este processo poder-se-ía colocar o seguinte código do campo “DisplayMode” da galeria onde estão os registos editáveis:
O código anterior coloca em modo de edição caso o dia actual seja inferior ao dia 16, no caso do dia ser maior ou igual a 16 os registos ficam impossibilitados de edição.
Ambas as soluções permitem de facto evitar edição dos dados a partir de determinado momento mas não são elegantes e muito menos facilmente configuráveis – o utilizador conseguirá aceder sempre à aplicação e tentará, com certeza, clicar e editar os registos. Mesmo colocando uma mensagem de aviso haveria um sentimento de que a app estaria com erros de edição.
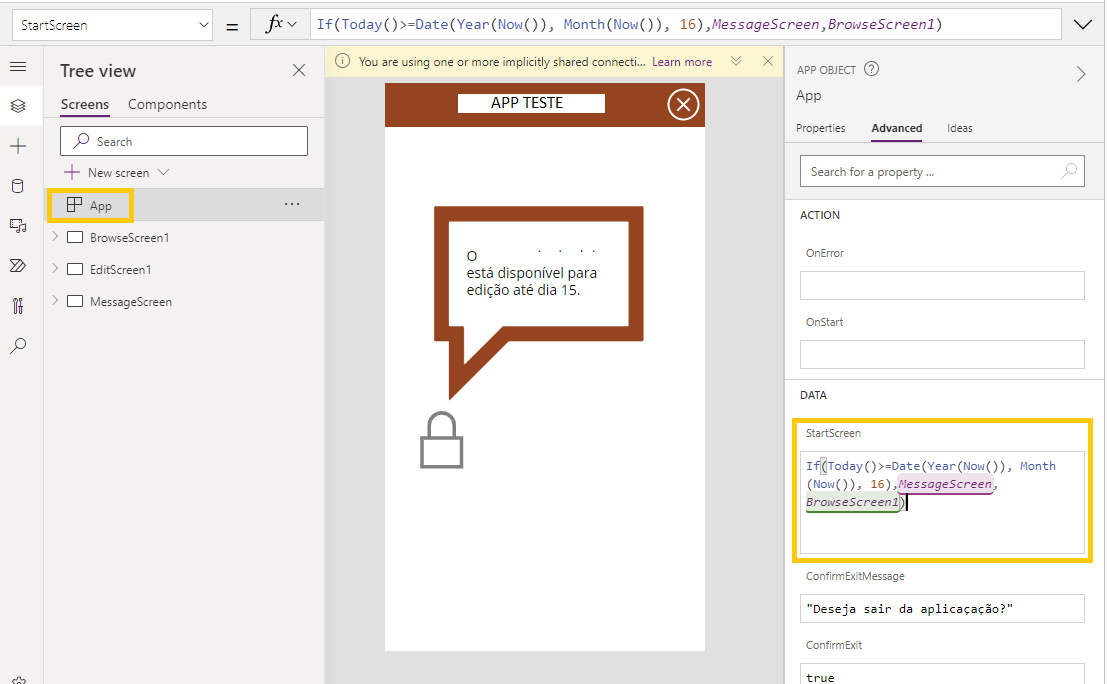
Uma forma mais elegante e que não deixará em dúvida o utilizador, será mostrar uma mensagem no acesso à app especificando que a mesma está bloqueada (porque ultrapassou determinada data) não havendo acesso ao seu interface gráfico de edição.
Esta será uma solução mais intuitiva e simples, e passará pelos seguintes passos:
Criar “New Screen” ou replicar um existente por forma a manter as formatações:
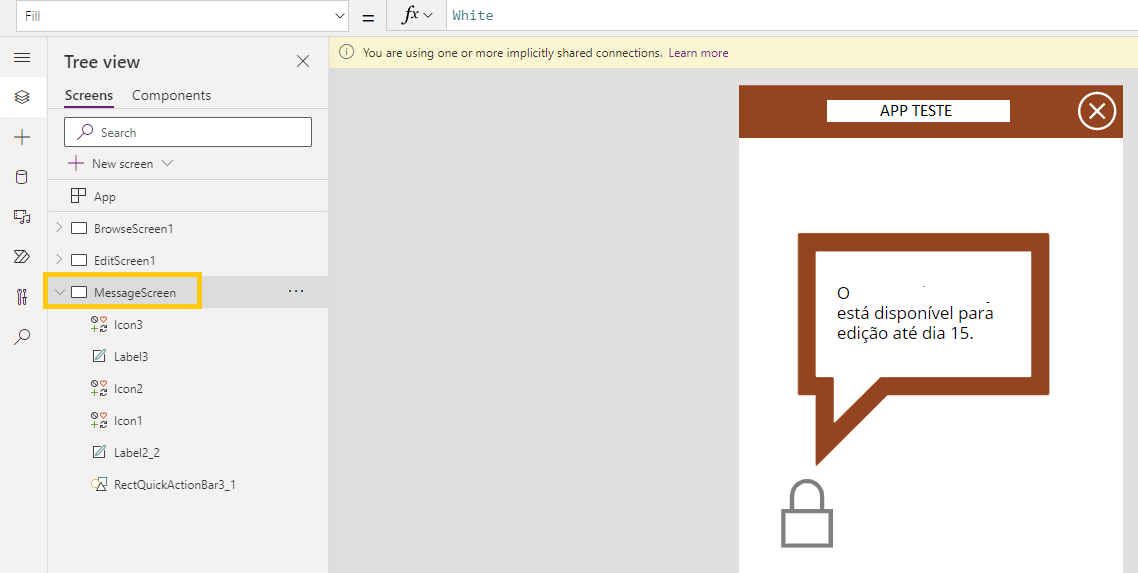
Alterar o nome do novo screen, optei por “MessageScreen”
Colocar no novo screen o que achar interessante para mostrar uma mensagem – no caso foram icons e labels:
Por fim, no objeto “App”, alterar o “StartScreen” colocando o seguinte código: If(Today()>=Date(Year(Now()), Month(Now()), 16),MessageScreen,BrowseScreen1)
Este código permite aceder ao screen de edição da app (“BrowseScreen1” ) até ao dia 15 de cada mês,inclusivé. Após esse dia será redirecionado para o screen “MessageScreen” onde apenas verá uma mensagem com aviso de indisponibilidade, com possibilidade de fecho da aplicação.
Forma muito rápida, simples e intuitiva de colocar uma app fora de serviço temporariamente.
Olá, o tema que trago aqui hoje, embora estranho para alguns, é de enorme importância na manutenção da performance aos dados no SQL Server. Trata-se da fragmentação que os índices das tabelas sofrem provocando lentidão no acesso aos dados.
A fragmentação dos índices é provocada por diversos factores, em tabelas onde existem muitos deletes, updates ou inserts o assunto é uma constante. Outra ação que leva à fragmentação é a compactação das DBs, sendo o mundo ideal nunca fazer shrink às mesmas.
O facto é que todos temos de realizar estas ações mais cedo ou mais tarde, porque a DB cresceu exponencialmente com alguma transação, ou porque o disco de repente ficou cheio e urge compactar a DB, ou simplesmente porque se eliminam dados e se inserem novos num contexto permanente. A solução estará na desfragmentação dos índices, quer seja através da reorganização (Reorganize) ou da reconstrução (Rebuild).
O script que vos trago permite realizar a verificação da fragmentação em determinada (s) DBs e, caso a percentagem de fragmentação seja superior a 5%, realizar uma das duas ações:
* Reorganize, caso a fragmentação esteja entre 5% e 30% * Rebuil, caso a fragmentação seja superior a 30%
Os scripts são baseados em Cursores percorrendo todas as DBs necessárias. Por acaso apenas especifico uma DB por questão de rapidez.
O código utiliza a função Rownumber() para escolher as linhas de índices únicas. Podem existir diversos índices para a mesma tabela, mas como faço o Reorganize ALL/Rebuild ALL devo apelar à unicidade – caso contrário estaria a tratar mais que uma vez o mesmo índice.
/*--------------------------------------------
INDEX REORGANIZE
fragmentation between 5 and 30
----------------------------------------------*/
DECLARE @Database NVARCHAR(255)
DECLARE @Table NVARCHAR(4000)
DECLARE @cmd NVARCHAR(1000)
DECLARE DatabaseCursor CURSOR READ_ONLY FOR
SELECT name FROM master.sys.databases
--WHERE name NOT IN ('master','msdb','tempdb','model','Testes') -- databases to exclude
WHERE name IN ('DB_User') -- specific databases
AND state = 0 -- database is online
AND is_in_standby = 0 -- database is not read only for log shipping
ORDER BY 1
OPEN DatabaseCursor
FETCH NEXT FROM DatabaseCursor INTO @Database
WHILE @@FETCH_STATUS = 0
BEGIN
SET @cmd = 'DECLARE TableCursor CURSOR READ_ONLY FOR
select tableName from (
SELECT ''['' + table_catalog + ''].['' + table_schema + ''].['' + table_name + '']'' as tableName
--,I.name as ''IndexName'',DDIPS.avg_fragmentation_in_percent
, row_number() over (partition by T.name order by I.name) As nlinha
FROM [' + @Database + '].INFORMATION_SCHEMA.TABLES A
INNER JOIN sys.tables T ON A.TABLE_NAME = T.NAME
INNER JOIN sys.dm_db_index_physical_stats (DB_ID(), NULL, NULL, NULL, NULL) DDIPS ON T.object_id = DDIPS.object_id
INNER JOIN sys.schemas S ON T.schema_id = S.schema_id
INNER JOIN sys.indexes I ON I.object_id = DDIPS.object_id AND DDIPS.index_id = I.index_id
WHERE
DDIPS.database_id = DB_ID()
AND I.name is not null
AND DDIPS.avg_fragmentation_in_percent between 5 and 30
AND A.table_type = ''BASE TABLE''
) kk
where nlinha=1'
-- create table cursor
EXEC (@cmd)
--PRINT(@cmd)
OPEN TableCursor
FETCH NEXT FROM TableCursor INTO @Table
WHILE @@FETCH_STATUS = 0
BEGIN
BEGIN TRY
SET @cmd = 'ALTER INDEX ALL ON ' + @Table + ' REORGANIZE'
PRINT @cmd
EXEC (@cmd)
END TRY
BEGIN CATCH
PRINT '---'
PRINT @cmd
PRINT ERROR_MESSAGE()
PRINT '---'
END CATCH
FETCH NEXT FROM TableCursor INTO @Table
END
CLOSE TableCursor
DEALLOCATE TableCursor
FETCH NEXT FROM DatabaseCursor INTO @Database
END
CLOSE DatabaseCursor
DEALLOCATE DatabaseCursor
Agora o código para o REBUILD dos índices:
/*--------------------------------------------
INDEX REBUILD
case fragmentation > 30
----------------------------------------------*/
DECLARE @Database NVARCHAR(255)
DECLARE @Table NVARCHAR(4000)
DECLARE @cmd NVARCHAR(1000)
DECLARE DatabaseCursor CURSOR READ_ONLY FOR
SELECT name FROM master.sys.databases
--WHERE name NOT IN ('master','msdb','tempdb','model','Testes') -- databases to exclude
WHERE name IN ('DB_User') -- specific databases
AND state = 0 -- database is online
AND is_in_standby = 0 -- database is not read only for log shipping
ORDER BY 1
OPEN DatabaseCursor
FETCH NEXT FROM DatabaseCursor INTO @Database
WHILE @@FETCH_STATUS = 0
BEGIN
SET @cmd = 'DECLARE TableCursor CURSOR READ_ONLY FOR
select tableName from (
SELECT ''['' + table_catalog + ''].['' + table_schema + ''].['' + table_name + '']'' as tableName
--,I.name as ''IndexName'',DDIPS.avg_fragmentation_in_percent
, row_number() over (partition by T.name order by I.name) As nlinha
FROM [' + @Database + '].INFORMATION_SCHEMA.TABLES A
INNER JOIN sys.tables T ON A.TABLE_NAME = T.NAME
INNER JOIN sys.dm_db_index_physical_stats (DB_ID(), NULL, NULL, NULL, NULL) DDIPS ON T.object_id = DDIPS.object_id
INNER JOIN sys.schemas S ON T.schema_id = S.schema_id
INNER JOIN sys.indexes I ON I.object_id = DDIPS.object_id AND DDIPS.index_id = I.index_id
WHERE
DDIPS.database_id = DB_ID()
AND I.name is not null
AND DDIPS.avg_fragmentation_in_percent > 30 --or T.name = ''STOCK''
AND A.table_type = ''BASE TABLE''
) kk
where nlinha=1'
-- create table cursor
EXEC (@cmd)
--PRINT(@cmd)
OPEN TableCursor
FETCH NEXT FROM TableCursor INTO @Table
WHILE @@FETCH_STATUS = 0
BEGIN
BEGIN TRY
SET @cmd = 'ALTER INDEX ALL ON ' + @Table + ' REBUILD'
PRINT @cmd
EXEC (@cmd)
END TRY
BEGIN CATCH
PRINT '---'
PRINT @cmd
PRINT ERROR_MESSAGE()
PRINT '---'
END CATCH
FETCH NEXT FROM TableCursor INTO @Table
END
CLOSE TableCursor
DEALLOCATE TableCursor
FETCH NEXT FROM DatabaseCursor INTO @Database
END
CLOSE DatabaseCursor
DEALLOCATE DatabaseCursor
Por fim, estes dois scripts podem ser inseridos em dois steps num único job SQL e feito o agendamento para ser executado durante a noite. E se durante a noite existirem processos de alteração de dados este script deverá correr após isso por forma a manter a boa performance para o próximo dia de trabalho.
Olá, este artigo sendo geral aplica-se , principalmente, à área de vendas a retalho onde o horário de abertura e de fecho das lojas é fundamental para, nomeadamente, o cálculo de objectivos de vendas.
Todos os meses será necessário o cálculo de objectivos de vendas para cada loja, sendo necessário planear o calendário de abertura/fecho para cada loja, principalmente nesta altura com tantas alterações repentinas por causa do COVID.
As ferramentas de suporte ao negócio apenas podem ajudar efectivamente o negócio após terem sido definidos os calendários mensais de cada loja. Esta acção deve ser desenvolvida pelos gerentes ou supervisores de lojas uma vez serem eles os detentores do conhecimento local.
A tarefa pode ser facilitada se lhes for fornecido um calendário pré-preenchido, ficando a seu encargo a validação e alguma alteração esporádica.
Este processo pode ser baseado nos horários do mês anterior, se determinada loja tem um horário “x” este mês será provável que para o próximo mês se mantenha. Mas aqui a proposta vai ainda mais longe, vamos basear o cálculo dos horários futuros na maior frequência de horário do mês anterior, isto é, na moda, para cada dia da semana.
Para se perceber melhor examinemos o seguinte cenário: Tomemos por base as sextas-feiras deste mês, para a loja nº1. Existem 4 sextas, com horário de abertura igual (open) e horário de fecho diferente (close).
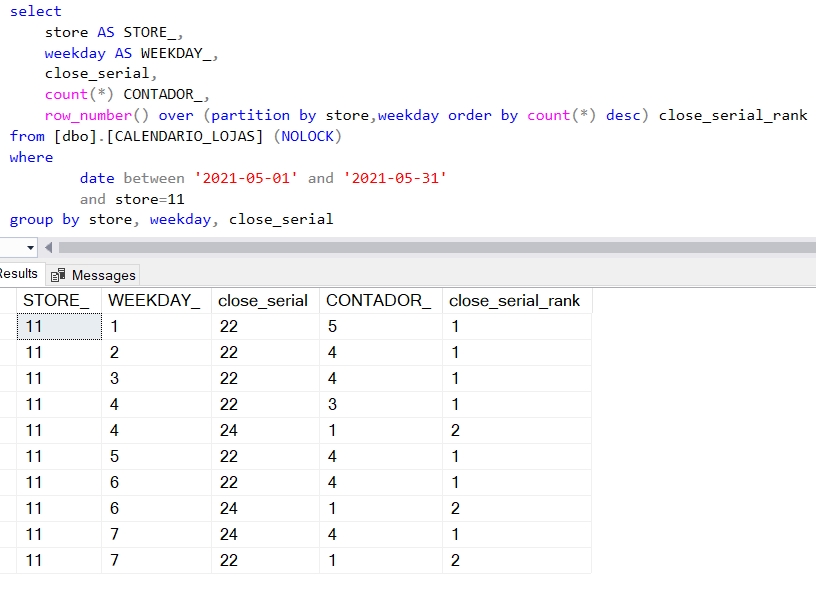
Percebe-se que a maior frequência (Moda estatística) para a hora de fecho é às 22 horas. Será este valor que deve ficar registado no horário de fecho das sextas-feiras do próximo mês a calcular (Junho). O cálculo para todos os outros dias de semana, para todas as lojas, é semelhante.
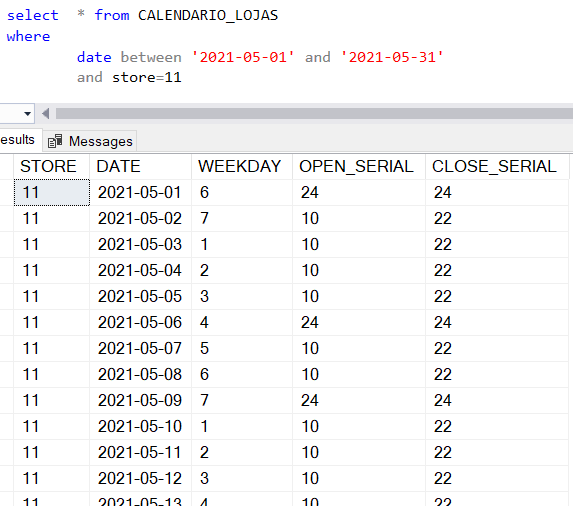
Iniciemos por analisar a tabela do calendário para o mês de Maio e, para facilitar, apenas para a loja nº 11:
O weekday 1 decidiu-se ser a segunda-feira.
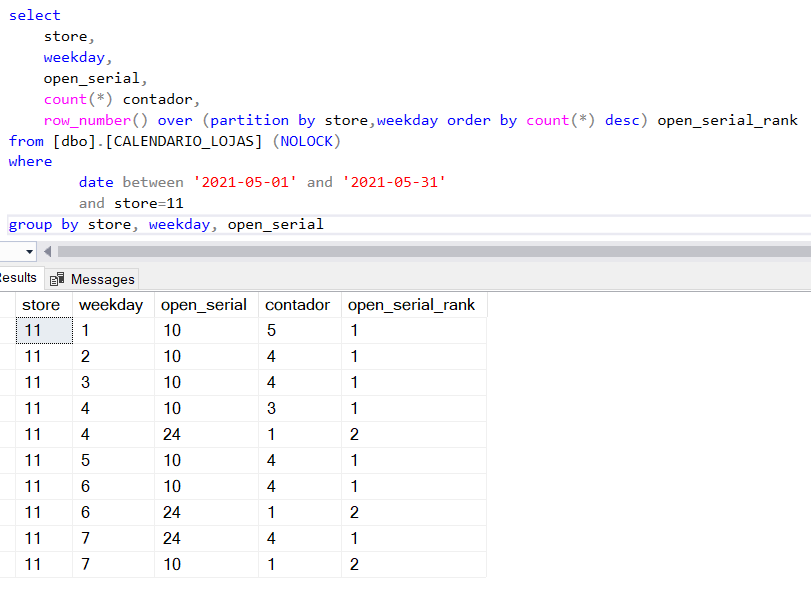
Vamos começar por calcular a Moda da hora de abertura do mês corrente e, para simplificar, apenas para a loja 11:
A coluna contador faz a contagem do número de vezes que cada hora de abertura está presente. A coluna open_serial_rank, baseada na partição por store/weekday, faz também uma contagem colocando o valor mais baixo para a contagem mais alta, isto é, o número mais frequente (maior valor em contador) é o que tem valor 1 (menor valor em open_serial_rank).
Repare-se por exemplo no weekday=4, tem 3 horários de entrada às 10 horas e 1 horário às 24 (na prática está fechado aqui!) – a Moda será 10. Já no weekday=7, o valor mais frequente para o horário de abertura é 24, isto é, a loja esteve maioritariamente fechada – será este estado a reflectir em Junho.
Apliquemos, agora, o mesmo processo para o cálculo da hora de fecho:
Repare-se por exemplo no weekday = 4 com 3 contagens de hora de fecho às 22 e uma contagem às 24 (fechado) – a Moda será 22, conforme especificado por close_serial_rank = 1.
Os valores da Moda serão os que se devem colocar posteriormente no calendário de Junho.
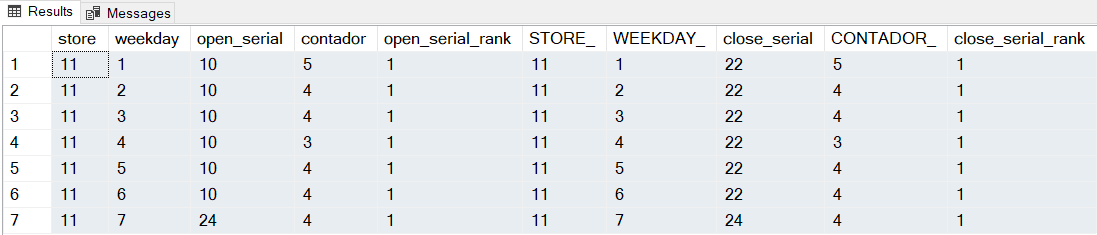
Agora basta juntar os dois códigos e obteremos a hora de abertura e a hora de fecho com mais frequência, isto é, onde open_serial_rank = 1 e close_serial_rank = 1:
/*
MODA ESTATÍSTICA SQL,
2021 JG
*/
select * from
(
select
store,
weekday,
open_serial,
count(*) contador,
row_number() over (partition by store,weekday order by count(*) desc) open_serial_rank
from [dbo].[CALENDARIO_LOJAS] (NOLOCK)
where
date between '2021-05-01' and '2021-05-31'
and store=11
group by store, weekday, open_serial
) KK
INNER JOIN
(
select
store AS STORE_,
weekday AS WEEKDAY_,
close_serial,
count(*) CONTADOR_,
row_number() over (partition by store,weekday order by count(*) desc) close_serial_rank
from [dbo].[CALENDARIO_LOJAS] (NOLOCK)
where
date between '2021-05-01' and '2021-05-31'
and store=11
group by store, weekday, close_serial
) JJ
on KK.store = JJ.STORE_ and KK.weekday = JJ.WEEKDAY_
where open_serial_rank=1 and close_serial_rank=1
Resultado:
Para cada um dos dias de semana ([1..7]) teremos agora a Moda de abertura (open_serial) e a Moda de fecho (close_serial). No Domingo, correspondente ao weekday 7, a loja estará fechada.
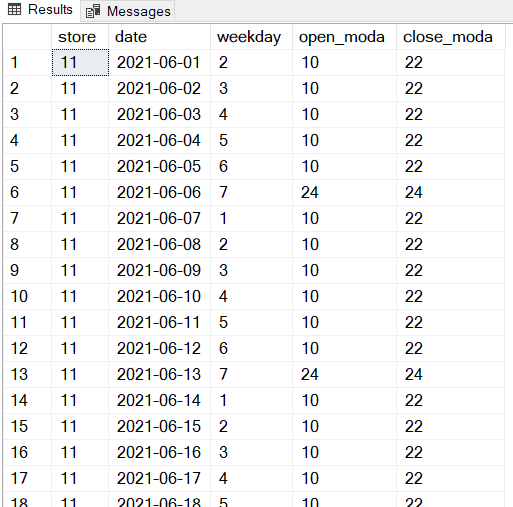
Para finalizar, basta cruzar este código com a tabela calendário para o mês futuro, Junho, assumindo as colunas de hora de abertura e fecho como sendo open_modae close_moda, respectivamente:
/*
MODA ESTATÍSTICA SQL,
2021 JG
*/
select HH.store,
HH.date,
HH.weekday,
DD.open_serial AS open_moda,
DD.close_serial AS close_moda
from [dbo].[CALENDARIO_LOJAS] (NOLOCK) HH
LEFT JOIN
(
select * from
(
select
store,
weekday,
open_serial,
count(*) contador,
row_number() over (partition by store,weekday order by count(*) desc) open_serial_rank
from [dbo].[CALENDARIO_LOJAS] (NOLOCK)
where
date between '2021-05-01' and '2021-05-31'
and store=11
group by store, weekday, open_serial
) KK
INNER JOIN
(
select
store AS STORE_,
weekday AS WEEKDAY_,
close_serial,
count(*) CONTADOR_,
row_number() over (partition by store,weekday order by count(*) desc) close_serial_rank
from [dbo].[CALENDARIO_LOJAS] (NOLOCK)
where
date between '2021-05-01' and '2021-05-31'
and store=11
group by store, weekday, close_serial
) JJ
on KK.store = JJ.STORE_ and KK.weekday = JJ.WEEKDAY_
where open_serial_rank=1 and close_serial_rank=1
) DD
ON HH.STORE = DD.STORE AND HH.WEEKDAY = DD.WEEKDAY
WHERE
HH.date between '2021-06-01' and '2021-06-30'
and HH.store=11
O resultado final com os “novos” horários para Junho, aqui com amostragem até dia 18, é:
Estes resultados podem ser armazenados numa tabela temporária para posterior alteração na tabela [CALENDARIO_LOJAS].
Para o cálculo de todas as lojas apenas será necessário retirar o filtro da loja 11.
Olá,
muitas vezes existem processos com necessidade de importação de dados de ficheiros texto para uma tabela SQL.
O BULK INSERT do SQL é uma boa ferramenta para esse efeito. A importação de um ficheiro para o SQL através de código com o BULK INSERT é algo básico; menos básico será a importação de diversos ficheiros, em diferentes pastas, para uma única tabela de SQL numa só importação.
Se a este processo se colocar a dificuldade de formatação dos ficheiros torna-se um processo moroso.
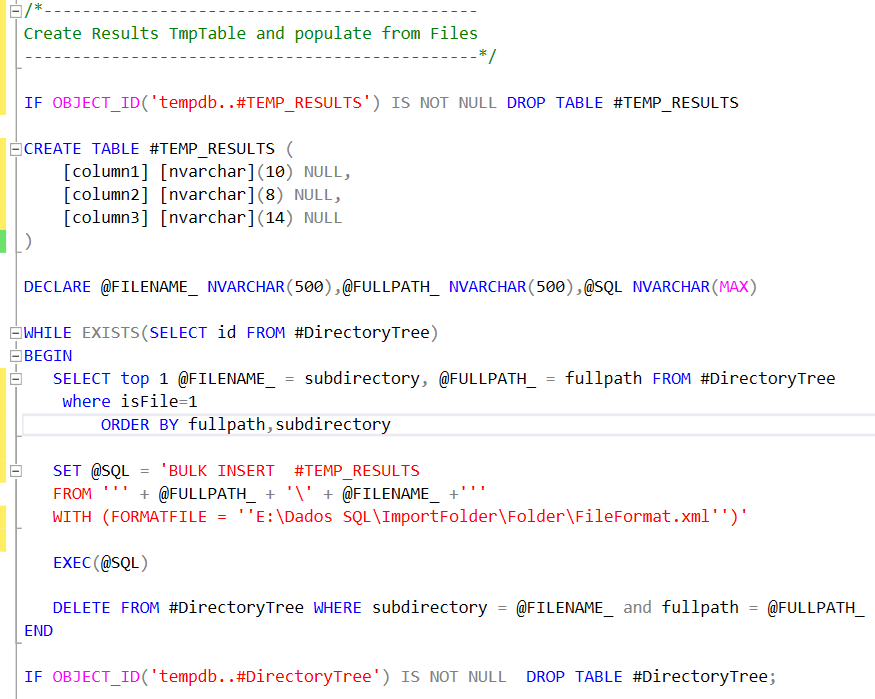
Com este artigo quero mostrar uma forma de importação de diversos ficheiros, em diferentes pastas, num único processo de SQL BULK INSERT, para uma única tabela. Além disso, mostro uma forma de importar os ficheiros de texto com largura de campos fixa, corrigindo problemas de formatação de colunas que poderiam surgir.
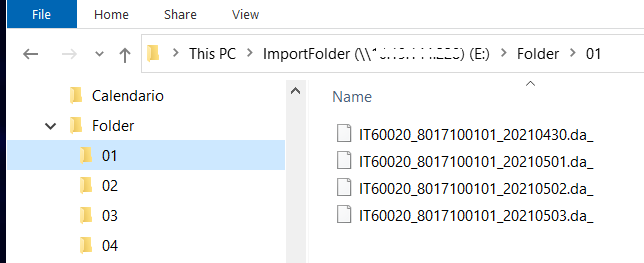
Assim, a minha estrutura de pastas e ficheiros é a seguinte:
Foi criada uma estrutura com uma pasta mãe denominada “Folder” e no seu interior diversas pastas “01“, “02“, etc.
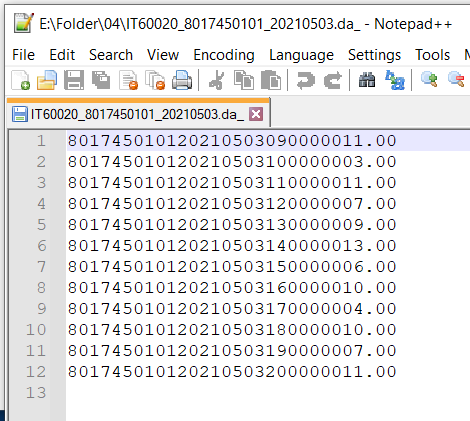
Dentro de cada uma destas pastas existem ficheiros de texto no seguinte formato:
Queremos juntar os dados dos diferentes ficheiros numa única tabela, mas devidamente separados por colunas de dados.
O script SQL passa por dois momentos:
Cria tabela temporária para popular com o caminho e nome dos ficheiros
Cria tabela temporária onde irá inserir os valores do ficheiros listados anteriormente , ou melhor, irá inserir os valores das colunas previamente criadas, através de um ficheiro de configuração XML, com as respectivas colunas de dados.
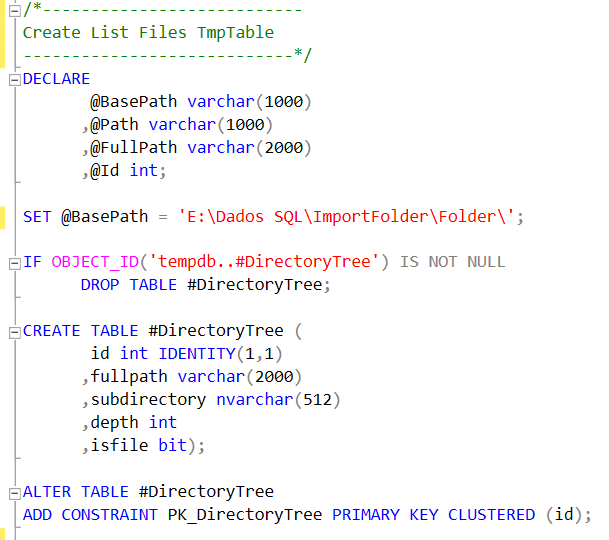
O primeiro passo será, então, criar a tabela temporária onde serão listados os ficheiros e respectivos caminhos de acesso aos mesmos. Além disso é criada um índice com intuito de melhor performance :
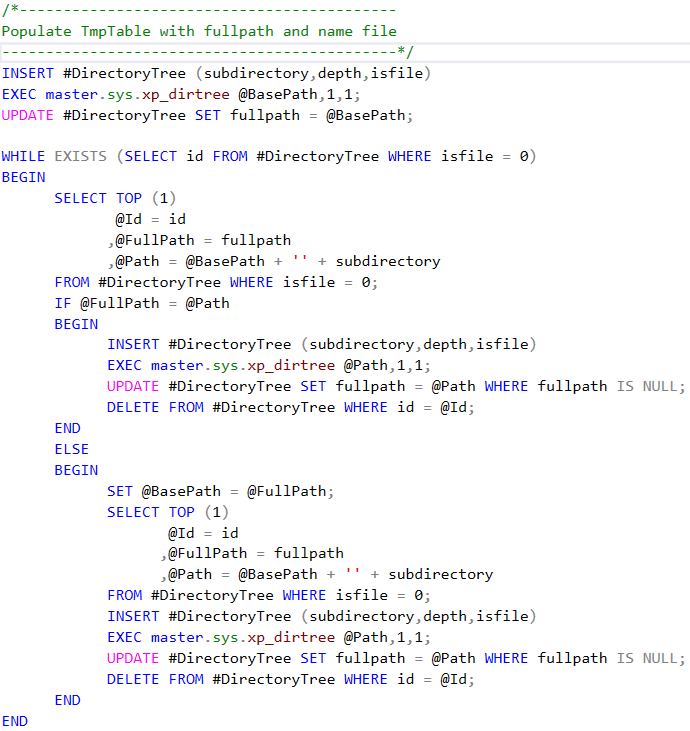
Agora vamos popular essa tabela:
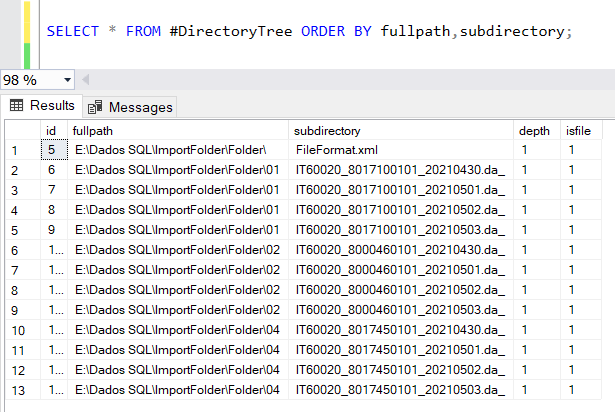
O resultado final do script anterior leva aos seguintes resultados, para o meu caso específico de pastas e ficheiros:
O ficheiro FileFormat.xml deve ser eliminado desta tabela temporária:
De seguida, vamos criar uma tabela temporária para armazenamento dos resultados finais, isto é, o Merge de todos os registos de todos os ficheiros existentes nas diferentes pastas. A criação de três colunas será explicada mais à frente:
O processo é idêntico a ter uma pilha (ou fila) de ficheiros que à medida que se insere um deles na tabela é eliminado dessa mesma pilha. Dessa forma, o número de ficheiro na pilha vai diminuindo até chegar a zero, altura que o ciclo termina.
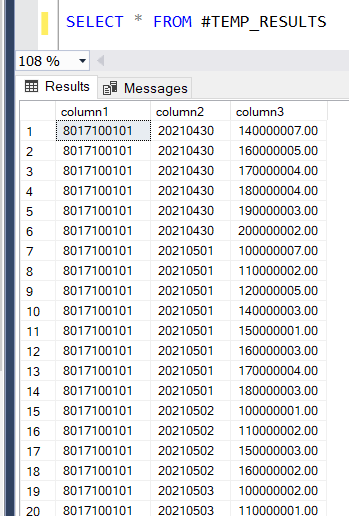
O resultado final da tabela temporária é este:
Repare-se na estrutura de dados fixa que foi criada com três colunas. Foi apenas um exemplo, poderiam ser mais e de diversos tipos.
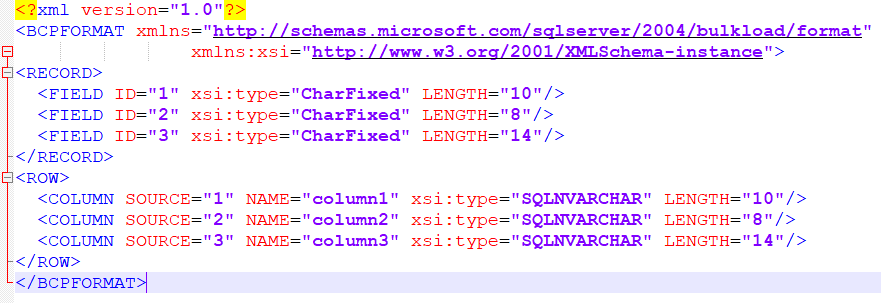
A formatação das colunas de valor fixo de largura e tipo de dados é configurada através do ficheiro FileFormat.XML listado acima.
O BULK INSERT utiliza o parâmetro de configuração de ficheiro externo (with FormatFile) permitindo a leitura em formato de diferentes campos fixos com consequente inserção no SQL.
O conteúdo do ficheiro de configuração FileFormat.XML é o seguinte:
Poderia ter optado por colocar mais colunas especificando seu tamanho e tipo, conforme fosse solicitado.
Por fim, todo o código poderá ser incluído numa Stored Procedure com o resultado final a ser incluído numa tabela física, procedendo posteriormente à eliminação da tabela temporária.
O NIF é constituído por nove dígitos, sendo os oito primeiros sequenciais e o último um dígito de controlo. Adicionalmente, o primeiro dígito do NIF não pode ser zero nem quatro.
Para ser calculado o digito de controlo:
Multiplicar 1º digito por 9, o 2.º dígito por 8, o 3.º dígito por 7, o 4.º dígito por 6, o 5.º dígito por 5, o 6.º dígito por 4, o 7.º dígito por 3 e o 8.º dígito por 2.
Seguidamente somar os resultados.
Calcular o resto da divisão do número por 11: se o resto for 0 (zero) ou 1 (um) o dígito de controlo será 0 (zero); se for outro qualquer algarismo X o dígito de controlo será o resultado da subtracção 11 – X.
Por fim, basta ver a igualdade do dígito de controlo com o último dígito do NIF. No caso de ser igual o NIF está correcto; no caso de ser diferente o NIF não é válido.
O código TSQL foi colocado como uma função. Esta é chamada com um NIF e o retorno será o próprio NIF se estiver válido ou vazio caso não o seja. Denominei a função como [dbo].[up_check_nif] e codifica-se da seguinte forma:
/*
Função valida NIF,
2021 JG
*/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
if OBJECT_ID('[dbo].[up_check_nif]') IS NOT NULL drop function dbo.up_check_nif
GO
CREATE function [dbo].up_check_nif (@nif_input varchar(9))
RETURNS varchar(9)
AS
BEGIN
declare @j int = 9
declare @i int = 1
declare @total int = 0
declare @digit_control int
declare @result varchar(9)
-- nif_pri_digito = '1,2,3,5,6,7,8,9'
IF LEN(@nif_input) = 9 AND @nif_input NOT LIKE '%[^0-9]%' AND LEFT(@nif_input,1) not in (0,4)
BEGIN
-- SUM( primeiros 8 digitos * [9,8,7,6,5,4,3,2])
WHILE @i < LEN(@nif_input)
BEGIN
SET @total = @total + SUBSTRING(@nif_input,@i,1) * @j
SET @j = @j-1
SET @i = @i+1
END
IF (@total % 11) = 0 OR (@total % 11) = 1
SET @digit_control = 0
ELSE
SET @digit_control = 11 - (@total % 11)
IF @digit_control = RIGHT(@nif_input,1)
SET @result = @nif_input /* nif válido */
ELSE
SET @result = '' /* nif inválido */
END
ELSE
SET @result = '' /* nif inválido */
RETURN @result
END
A função poderá ser chamada da seguinte forma:
select dbo.up_check_nif(‘123456789’) AS NIF_Validado
A equipa de marketing quer lançar uma nova campanha cujo objectivo é convencer os clientes a abrir depósitos a prazo.
Até agora a estratégia era ligar ao máximo número de pessoas, de forma indiscriminada, e tentar vender-lhe o produto. No entanto essa abordagem, para além de gastar mais recursos porque implica ter várias pessoas a ligar a todos os clientes, também é incómoda para alguns clientes que não gostam de ser incomodados com esse tipo de chamadas. Feitas as contas, chegou-se à conclusão que:
- Por cada cliente identificado como um bom candidado, e é alvo da campanha mas não adere ao depósito a prazo, o banco tem um custo de 500 euros.
- Por cada cliente que é identificado como mau candidado, e como tal não é alvo da campanha mas na verdade era um bom candidado e iria aderir, o banco tem um custo de 2000 euros.
Com base nesta informação, conseguem ajudar a equipa de marketing criando um modelo que seleccione os melhores candidatos para serem alvos da campanha, de forma a reduzir custos?
O dataset contêm informação sobre todos os clientes que foram alvo da campanha:
1 - age
2 - job : type of job
3 - marital : marital status
4 - education
5 - default: has credit in default?
6 - housing: has housing loan?
7 - loan: has personal loan?
8 - pdays: number of days that passed by after the client was last contacted from a previous campaign
9 - previous: number of contacts performed before this campaign and for this client
10 - poutcome: outcome of the previous marketing campaign
11 - emp.var.rate: employment variation rate - quarterly indicator
12 - cons.price.idx: consumer price index - monthly indicator
13 - cons.conf.idx: consumer confidence index - monthly indicator
14 - euribor3m: euribor 3 month rate - daily indicator
15 - nr.employed: number of employees - quarterly indicator
Output:
y: has the client subscribed a term deposit?
Perguntas:
1. Quantas features estão disponíveis? Quantos clientes?
2. Quantos clientes têm no dataset que efectivamente aderiram ao depósito a prazo? E quantos não o fizeram?
3. Quais são as features mais relevantes para decidir se um cliente tem mais propensão para aderir ao depósito a prazo?
4. Qual o algoritmo que levou aos melhores resultados?
5. Qual/Quais as métricas de avaliação que usaram para comparar a performance dos vários modelos? Porquê?
6. Qual é o custo que o banco tem sem nenhum modelo?
7. Qual o custo que o banco passa a ter com o vosso modelo?
O projecto divide-se praticamente em cinco partes com todos os componentes desejados num processo de Data Science:
1) Análise, tratamento e transformação dos dados: remoção de variáveis, outliers, transformação de variáveis categóricas em numéricas, etc
2) Criação de uma Baseline da campanha imaginando que todos as pessoas acederiam à mesma
3) Procura dos melhores hiper-parâmetros dos diversos modelos a testar (é aqui que o processamento pode demorar horas!)
4) Criação dos modelos de machine learning, com os hiper-parâmetros recolhidos anteriormente
5) Análise dos resultados de todos os modelos testados e selecção do melhor, o que dará menor custo à campanha. Verificação das melhores features a usar no modelo.
No repositório existe também o dataset em formato csv.
Sintam-se à vontade para utilizar o código, espero que vos seja útil!
Olá, o artigo de hoje tem por objectivo facultar um script de pesquisa de stored procedures SQL através de qualquer palavra chave que nos recordemos.
Imaginemos que queremos saber se existe alguma “stored procedure” relacionada com a palavra “irregularidade”, mas que não sabemos de facto de existe ou qual seu nome – algo muito comum pelo menos comigo!
Para o caso a analisar, atentemos o seguinte código SQL:
select top 10 * from sys.syscomments where text like ‘%irregul%’
Este código permite pesquisar sp com uma palavra chave que imaginamos possa existir :
Do resultado obtido, a reter será o “id” e a coluna “text”, sendo respectivamente o identificador e o conteúdo do objecto SQL.
De seguida, poderemos escrever a seguinte linha de código:
select top 10 * from sys.all_objects where object_id=’178405579′
que nos mostra os objectos “stored procedures”, cuja identificação é ‘178405579’, ou seja, a mesma retirada do código anterior “id”.
Atente-se no resultado obtido onde se pode verificar que é uma “stored procedure”, em que data foi criada e alterada e respectivo nome.
Já agora, o top 10 neste caso não serve para nada, é apenas uma questão de não stressar o SQL no caso de existirem muitos registos.
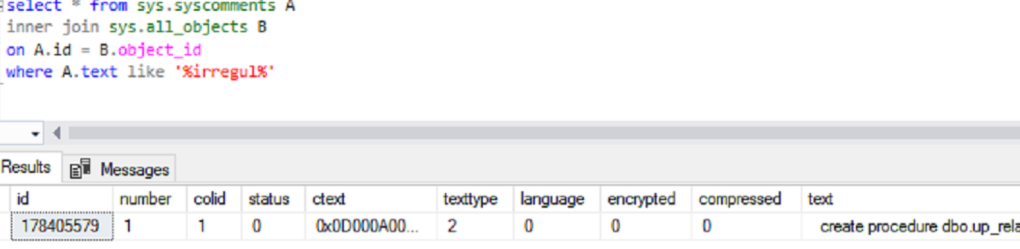
Por fim, poderemos juntar ambos os códigos e cruzar as tabelas obtendo um script simples e mais intuitivo:
select * from sys.syscomments A inner join sys.all_objects B on A.id = B.object_id where A.text like ‘%irregul%’
Repare-se que a palavra chave pode ser mesmo qualquer coisa que pensemos existir no processo, poderia ser uma variável como “@irreg”.
O resultado está na imagem seguinte:
Só falta mesmo construir o script com a definição da variável no topo de forma a alterar a mesma na pesquisa…mas como o código é demasiado pequeno não me dou ao trabalho, basta alterar a palavra chave no código acima.
Espero que vos seja útil,
JG
Assistência técnica TI, Desenvolvimento de aplicações, Desenvolvimento de sites e Segurança informática jorge_gomes98@hotmail.com Telm: 962988116